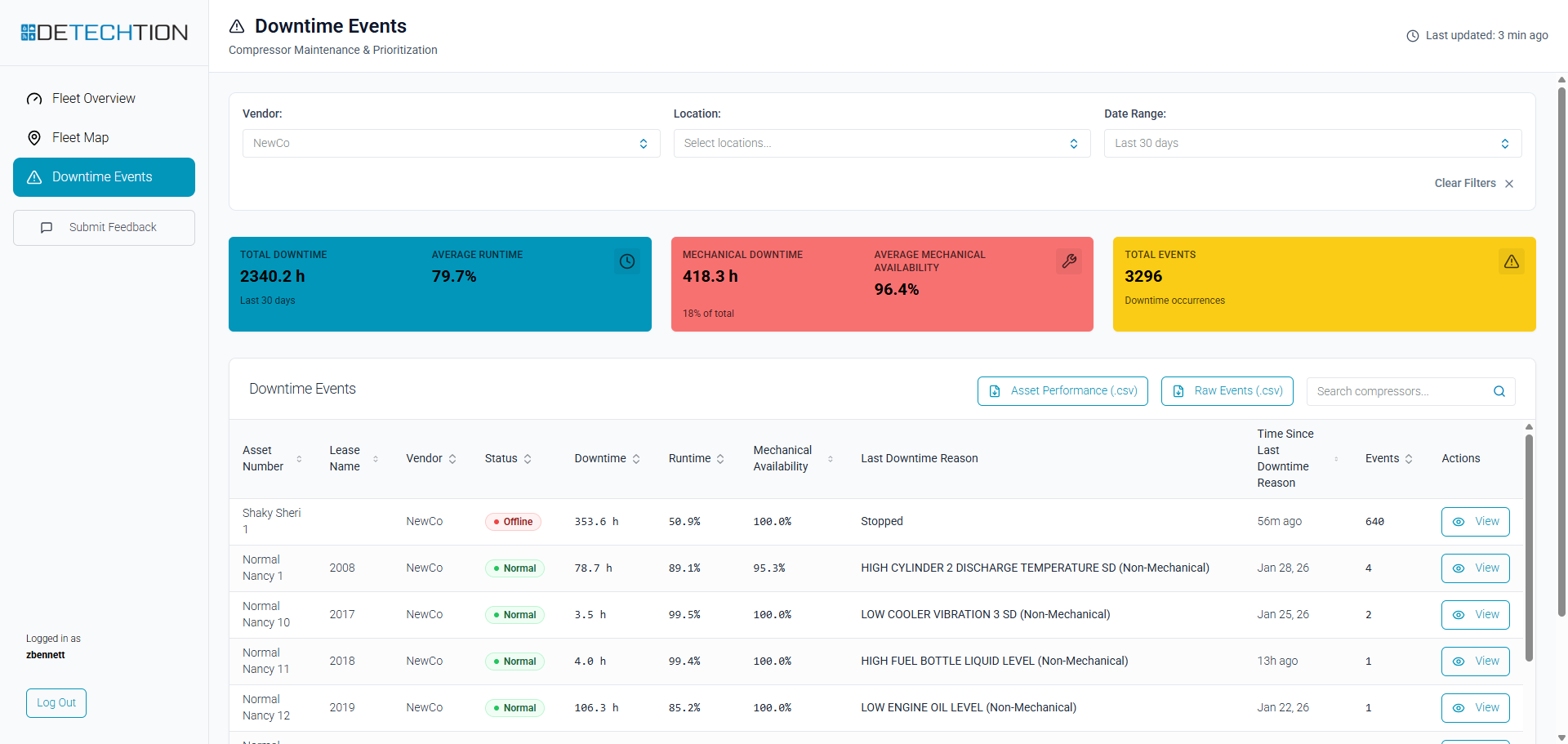
For many operators, managing a fleet of gas compressors still means responding to shutdowns after they happen, troubleshooting recurring issues without enough context, and making decisions with fragmented data. That makes it harder to protect uptime, control cost, and improve performance before problems escalate.
Moving to a more proactive approach starts with better visibility into what the fleet is doing today and what is affecting overall compressor performance. In the first episode of our Know Pressure: Your Guide to Compressor Fleet Management webinar series, we focused on two core drivers of compressor fleet performance: runtime and utilization.
Key Takeaways:
- Proactive compressor fleet management often starts with better visibility.
- Compressor runtime and utilization are key measures of compressor performance.
- Tracking compressor shutdown causes helps reduce avoidable downtime.
How Runtime and Utilization Reveal Performance Issues
One of the clearest ways to move from reactive to proactive compressor fleet management is to improve runtime across the fleet.
During the first episode of our webinar series, we focused on runtime and utilization to show how operators can begin moving from reactive to proactive fleet management. This included why many fleets still operate reactively, how limited visibility makes it harder to identify performance gaps, and why even small improvements in uptime or loading can have a meaningful impact on production, operating cost, and overall fleet efficiency.
Jump to a Topic:
- What compressor fleet management means and why it matters (3:25)
- Common challenges compression operators face today (4:55)
- Runtime benchmarks across 10,000 monitored compressor assets (9:00)
- Why tracking shutdown causes matters as much as tracking runtime (11:00)
- How setpoints and configuration changes can reduce preventable shutdowns (12:15)
- Utilization benchmarks across 10,000 monitored compressor assets (15:45)
- How an Australian operator improved utilization and increased production (17:00)
- Why continuous improvement is essential for compressor optimization (20:00)
Start With a Clear Compressor Runtime Baseline
Better runtime visibility starts with knowing where the fleet stands today. Across the 10,000 compressors we monitor, average runtime is about 89%. During the webinar, we broke that down further to roughly eight shutdowns per month per compressor, with each shutdown lasting an average of eight hours.
That is more than a benchmark. It is a reminder that repeated shortfalls in runtime can quietly add up to lost production, higher labor demand, and more operational disruption than many teams realize. If operators do not have a clear baseline for runtime across the fleet, it becomes much harder to see where performance is slipping or where attention is needed first.
Use Downtime and Utilization Data to Find Opportunities
Tracking runtime is useful, but tracking the reasons behind downtime is where improvement starts. Knowing that a unit shut down is only the first step. Knowing whether shutdowns are tied to suction pressure, discharge conditions, controls, or configuration issues gives teams something they can actually act on.
Some shutdowns may be more preventable than they appear. During the webinar, we pointed to examples where high- or low-suction-pressure shutdowns can sometimes be reduced through better setpoints and configuration decisions. Those may be relatively low-cost changes, but they can still improve runtime and reduce unnecessary interruptions across the fleet.
We also discussed a published case study involving an Australian operator that improved compressor utilization over time through a structured optimization effort. The broader takeaway is that better data and a repeatable improvement process can help operators uncover hidden production opportunities.
How to Start Shifting From Reactive to Proactive Compressor Fleet Management
Improving runtime is one of the clearest starting points, but the larger goal is to build a process that supports better decisions across the fleet over time.
1. Measure runtime across the fleet.
Operators need a clear view of which assets are running, how often they shut down, and how long they stay down. Without that baseline, it is difficult to know where performance is being lost or which assets need attention first.
2. Track the reasons behind downtime.
High-level uptime numbers matter, but the real value comes from understanding why shutdowns happen. This is where fleets begin to move beyond reacting to symptoms and start identifying repeatable causes.
3. Look for low-cost opportunities first.
Not every improvement requires major capital spending. In some cases, setpoint changes, control adjustments, or configuration changes may reduce avoidable downtime or improve loading without larger equipment modifications.
4. Build a continuous improvement process.
Proactive fleet management is not a one-time project. It requires regular review of data, analysis of performance gaps, action on findings, and follow-up to measure results. That cycle is what helps organizations move from isolated fixes to repeatable operational improvement.
Ready to Take the Next Step?
Moving from reactive to proactive compressor fleet management starts with visibility, but it only creates value when teams use that visibility to make better decisions. The more clearly operators can see runtime performance, shutdown causes, and improvement opportunities, the better positioned they are to reduce avoidable downtime and improve results across the fleet.
At Detechtion, we help oil and gas operators optimize compression and other critical production assets with solutions that turn operating data into action. Backed by decades of compression expertise, our Compression Optimization Suite helps teams turn operating data into action to improve performance, manage risk, and operate more efficiently.
Read our Complete Guide to Compressor Fleet Management for a broader look at how operators can improve visibility, performance, and decision-making across the fleet.